What is data lineage and why is it important?
Data lineage is the process of tracing and documenting the journey of data as it flows from its origin through various transformations, pipelines, and storage systems to its final use in applications, reports, or models. It provides visibility into how data is sourced, how it’s manipulated, and where it’s ultimately consumed. For AI applications, which rely heavily on large volumes of high-quality data, data lineage plays a key role in ensuring transparency, consistency, and reliability throughout the development lifecycle. It enables teams to understand not just what data is used, but how it has evolved over time and across systems.
In AI, data lineage is especially important for ensuring model accuracy, fairness, and accountability. By understanding where data comes from and how it has been processed, teams can validate model inputs, reproduce experiments, and identify the root cause of unexpected model behavior. It also supports compliance with data privacy and governance regulations, such as GDPR or HIPAA, by making it easier to track and manage sensitive data. Data lineage helps build trust in AI systems by providing the transparency needed to audit, explain, and continuously improve AI outcomes.
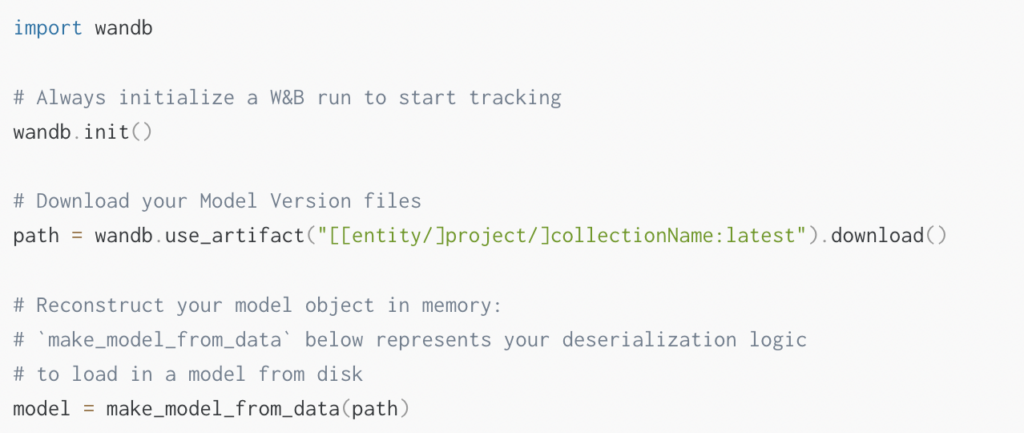
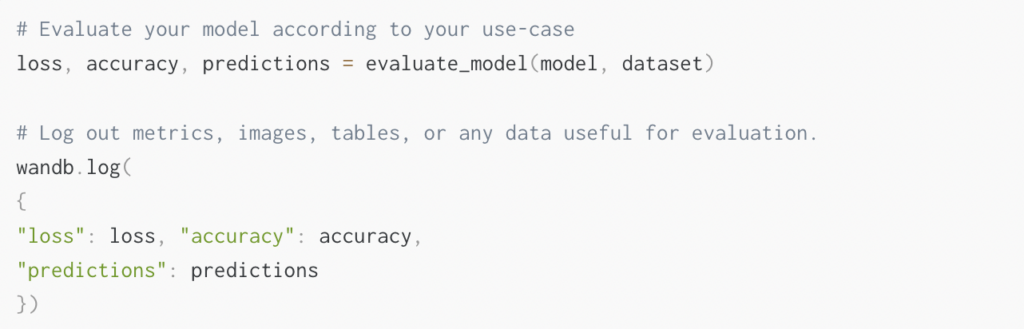
What is a model registry in ML?
In ML, a model registry is a centralized repository or model store, similar to a library, that lets you effectively manage and organize machine learning models. It is where models are stored, tracked, versioned, and made accessible to anyone at the company involved in deploying and using models in production.
This will likely include ML practitioners, data scientists, software developers, product managers, and other.
The model registry should provide model lineage for experimentation, model versioning records when models were pushed to production, and annotations from collaborators. It acts as a secure and organized repository that’s accessible across your org, streamlining model development, evaluation, and deployment.
The model registry also allows the entire team to manage the lifecycle of all models in the organization collaboratively. Your data scientists can push trained models to the registry. Once in the registry, the models can be tested, validated, deployed to production by MLOps, and evaluated continuously. This is, in many ways, quite similar to software DevOps.
Let’s look at the benefits of both in detail: