
Six years ago, the tools needed to realize the potential of deep learning didn’t exist. We started Weights & Biases to build them. Our tools have made it possible to track and collaborate on the colossal amount of experimental data needed to develop GPT-4 and other groundbreaking models.
Today, GPT-4 has incredible potential in applications for humanity, but that potential far exceeds our ability to actually apply it. To solve this, we need to think differently about how we build software. We need new tools.
We’re very proud to announce public availability of Weave, a suite of tools for developing and productionizing AI applications.
Use Weave to:
Go to https://wandb.me/weave to get started.

Generative AI models are incredibly powerful, but they are non-deterministic black boxes by nature. We now know that it’s easy to make incredible AI demos, but it takes significant engineering effort to make production applications work.
This difficulty arises from the stochastic nature of AI models. The input space for any given application is far too large to completely test.
But there is a solution: treat the model as a blackbox and follow a scientific workflow, akin to the workflow machine learning practitioners use to build these models in the first place.
Here’s how it works:
Weave introduces minimal abstractions that make this process a natural part of your workflow.
The first step toward harnessing the power of AI models is to log everything you do to a central system-of-record.
You’ll use this data to understand what experimental changes have impact, build up evaluation datasets, and improve your models with advanced techniques like RAG and fine-tuning.
What do you need to track?
Weave makes this easy. Wrap any Python function with @weave.op(), and Weave will capture and version the function’s code, log traces of all calls, including their inputs and outputs.
Call @weave.init(“my-project”) to enable Weave tracking, and then call your function as normal.

If you change the function’s code and then call it again, Weave will track a new version of the function.

Weave Objects use the pydantic library under the hood. You can instantiate and call them like this:
Weave Objects are organized and versioned automatically as well. Now that we’ve extracted the prompt template from inside the function’s body, it is queryable. You can easily filter down calls to those that used a specific word in their prompt template.
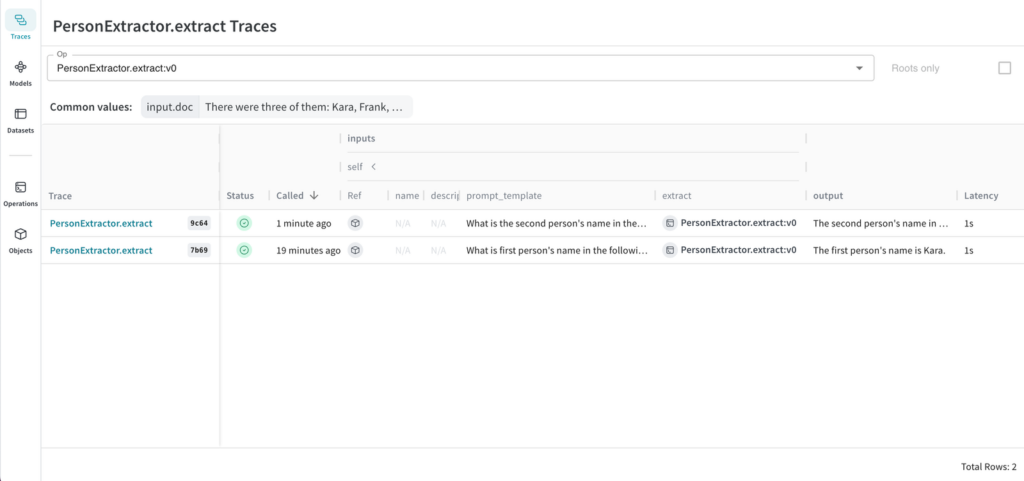
You should use Weave tracking in development and production, to easily capture and organize all the valuable data generated by your AI development process.
Evaluations are like unit tests for AI applications. But since AI models are non-deterministic, we use scoring functions instead of strict pass/fail assertions.
You should continuously evolve a suite of Evaluations for any AI applications that you build, just like you would write a suite of unit tests for software.
Here’s a simple example:
Here are the results:

Looks like our model is also extracting the names of cats. We should be able to fix it with a little bit of prompt engineering.
With Evaluations you can spot trends, identify regressions, and make informed decisions about future iterations.
There’s a lot more to discover in today’s release. Head on over to http://wandb.me/weave to get started.
The best way to build great tools is to talk to users. We love feedback of all varieties. Please get in touch: @weights_biases on X, or email: support@wandb.com