
For more information or if you need help retrieving your data, please contact Weights & Biases Customer Support at support@wandb.com
In software engineering, it’s common practice to use version control to keep track of changes, ensure traceability and enable collaboration. But version control isn’t just useful in software development – it’s vital in machine learning (ML). Instead of only versioning source code, we also need to version data and models, which are important artifacts in ML.
This article will give you a quick refresher on version control in general and explain how it’s used in ML. Then we will discuss why data and model versioning is important.
This article is the third of a small article series related to MLOps. Be sure to read the previous articles about Experiment Tracking in Machine Learning and Hyperparameter Optimization.
Before diving into data and model versioning in ML, let’s brush up on some general key concepts of version control. We’ll cover the definition of version control, a few central terms, why version control is useful, and the three types of version control.
Version control describes tracking and managing changes made to files or project folders over time.
Some key concepts of version control are:
The use of version control goes beyond saving different versions of a file or project. Its main advantages are traceability, reproducibility, rollback, debugging, and collaboration.
Version control comes in various shapes with its advantages and disadvantages. Although you can manually version your files, using a version control system is standard practice. We differentiate three types of version control systems: local, centralized, and distributed.
Does the below picture look familiar to you? When we need to differentiate between different versions of a file for the first time, we intuitively store the same file under different names to distinguish the different versions from each other.

Manual version control has only one advantage (it’s rather easy) and many drawbacks (oh so many). While this type of version control requires no setup effort, it is difficult to understand the history of changes, leaving little possibility for collaboration with others. If your disk is damaged, all changes will be lost.
That’s why it is standard practice to use version control systems instead of manually versioning files and projects.
We differentiate between 3 types of version control systems, which are visualized below:
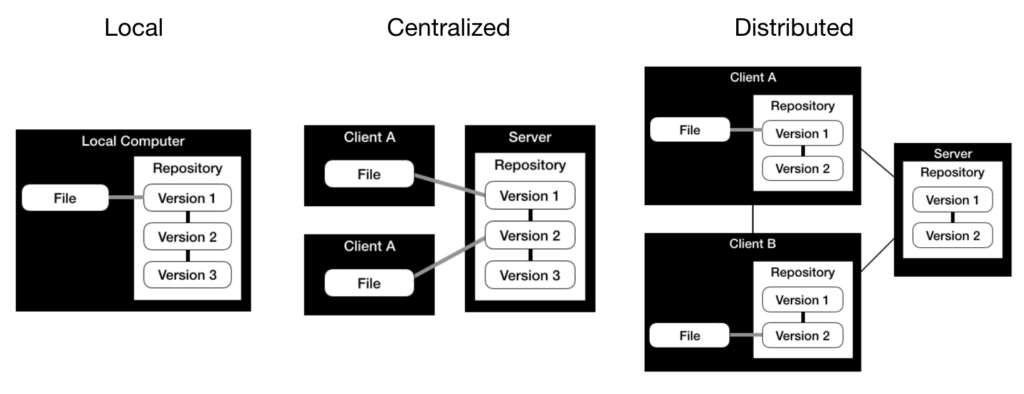
Version control is not only useful in software development but in the development process of ML models as well. In ML, versioning source code is as important as versioning artifacts like datasets and models.
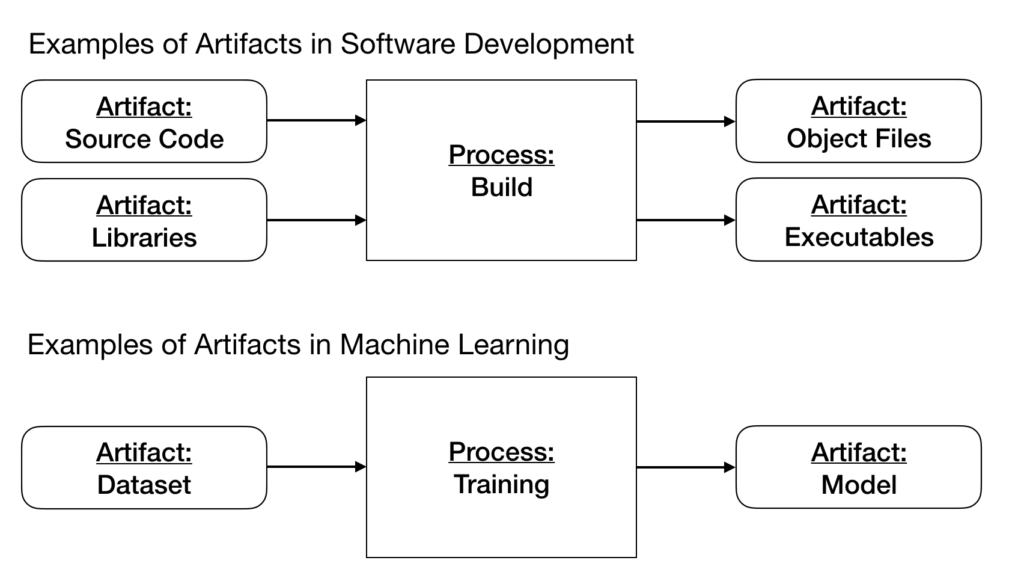
During the development process of an ML model, we create artifacts other than source code. An artifact is any file that is an input or an output of a process. Examples of artifacts in software development that inputs are source code and libraries as inputs of a process. In contrast, object files and executables are example artifacts that are outputs of a process. In this example, the process is a build process.
In ML, the most important artifacts are datasets and models. For example, a dataset would be an artifact that is an input of a training process, while a model would be an artifact that is an output of it.
While version control is typically associated with source code, model version control or model versioning specifically indicates the version control of data in ML. It describes the practice of storing, tracking, and managing the changes in a dataset.
A new version of a dataset can be stored for the following events during the model development process:
Similarly to how data versioning indicates the version control for data in ML, model version control or model versioning specifically indicates the version control of ML models. It describes the practice of storing, tracking, and managing the changes in an ML model.
For model version control, we need to define two more terms to differentiate from the term “model version” [2].
Registered models are saved in a model registry. You can think of a model registry as a repository for your registered models. While you could use an artifact repository like JFrog’s Artifactory to store your ML models, a model registry is specifically intended for storing and managing ML models, including versioning, lineage, and lifecycle management.
While data version control is mostly relevant for model development, model management, including model version control, applies to the complete model lifecycle from training through staging to production.
If you are interested in implementing data and model version control for your ML models, there are various MLOps platforms and tools that incorporate data and model versioning, such as DVC, Neptune, or Weights & Biases.
For a practical guide on how to use W&B Artifacts for data and model versioning in Python, you can watch the below video walkthrough with the accompanying interactive Colab notebook:
All version control best practices for source code apply to data and model versioning as well. This section will also cover what you additionally need to consider to document version control in ML properly.
Let’s cover some basic best practices when it comes to version control in general:
The above points apply to versioning source code, datasets, and ML models alike. If you are versioning datasets and ML models, you should also consider separating productive and logging code: Any productive code, like data preprocessing or modeling and training, should be separated from the code used to load and save a version of the dataset or model.
This article has discussed the importance of version control in ML. Not only is it helpful to version source code, but important ML artifacts like datasets and models at different stages of the ML model lifecycle.
Version control is important for any artifact because it helps with traceability, reproducibility, rollback, debugging, and collaboration - whether for source code, datasets, or ML models. Version control can be done in different degrees of collaboration and backup capabilities from local, to centralized, to distributed version control systems.
While in software development, important artifacts other than source code can be libraries, object files, or executables, in ML, important artifacts, which need versioning, are datasets and models. Thus, we need to consider version control for datasets and ML models in ML. While data versioning is most important for model development, model versioning is important for the whole model lifecycle.
Thus, ML models are versioned in a special repository, called a model registry, for storing and managing different model versions throughout the entire model lifecycle.
[1] git (2023). About Version Control. (accessed January 2023)
[2] Weights & Biases Inc., (2022). Documentation (accessed December 2022)